ちょっとおさらいをしておくと、
・通帳のスキャンに使用するスキャナーはScanSnapS1100
・OCRソフトはe.Typist
・通帳は頭やお尻からではなく横からスキャナーに挿し込んで読み込ませる
・スキャナーに挿し込む前に通帳のページはよく開いておく
・通帳には余計なカキコミはしない
・スキャナーの設定は「スーパーファインモード・白黒・PDF形式」
・三菱○京UFJの通帳はクソ
・ゆう○ょ銀行の通帳も意外とクソ(← NEW!)
・OCRソフトはe.Typist
・通帳は頭やお尻からではなく横からスキャナーに挿し込んで読み込ませる
・スキャナーに挿し込む前に通帳のページはよく開いておく
・通帳には余計なカキコミはしない
・スキャナーの設定は「スーパーファインモード・白黒・PDF形式」
・三菱○京UFJの通帳はクソ
・ゆう○ょ銀行の通帳も意外とクソ(← NEW!)
といった感じ。
で、今日はe.Typistの認識字種設定について。
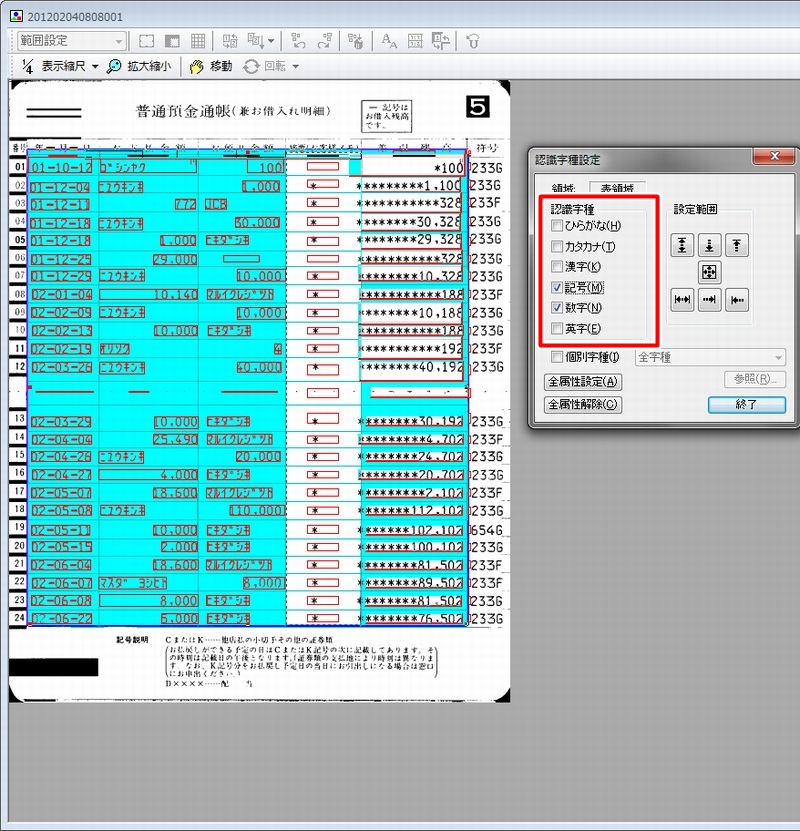
e.Typistは表の列ごとに字種を設定することが出来る。
今回のような預金通帳の読み取りには非常に効果的なので上手に使いたい。
「年月日」列
記号・数字のみチェック基本的に数字と「-(ハイフン)」のみの列なので認識率も高いはずと期待するのだが、意外にそれほど高くなかったりもする。
例えば、左端の通帳行番号が「年」の数字にかかってしまったり。
あるいは、次の通帳(三菱東京UFJ)のようにハイフンが数字にかぶってしまう場合。

このような場合は、ハイフン込で数字を辞書に登録してハイフンは捨て。
あとで修正。Excelなら、Excel先生ならきっとなんとかしてくれる!
「摘要」列
通帳によって異なるので適宜データとしては重要性はそれほど高くないのでまぁ適当に
「お支払金額」・「お預り金額」列
金額だけでなく、反対側の金額に対応する振込先等が記載されることが多い。金融機関(通帳)によって漢字の有無などあるので字種設定は適宜。
ひらがなはおそらくほとんど使われないので外してもOKかと。
問題は英字にチェックを入れるかどうか。
アルファベットを使用した振込先等やが記載されることは少なくないが。
たとえそれらの認識率を落とすことになるとしても英字は外した方が良いように思う。
これを入れると肝心の「金額の認識率」が下がるからだ。
例えば
0(ゼロ) → o(オー)
1(イチ) → i(アイ)
2(ニ) → z(ゼット)
5(ゴ) → s(エス)
6(ロク) → b(ビー)
など。1(イチ) → i(アイ)
2(ニ) → z(ゼット)
5(ゴ) → s(エス)
6(ロク) → b(ビー)
前にも書いたが、摘要欄に多少誤字があっても大した問題ではない。
例えば「GOOGLE」(ジーオーオー〜)が「G00GLE」(ジーゼロゼロ〜)と書いてあっても読めちゃうし。
もちろん必ずしも読めちゃうとは限らないが、気になるレベルのものは後でまとめて修正すれば良い。
それよりも金額が正しく認識されないというのは問題だ。
通帳のフォントによっては「英字」にチェックを入れたままでも金額の認識率が高い場合もあり、この辺は様子を見ながら、といった感じか。
「差引残高(現在高)」列
記号・数字のみでOK。この列は認識率がかなり高いと思う。
「符号(記号・店番号)」などの列
会計処理には不要なデータのため認識範囲外ちなみに、残高列の金額自体はそもそも会計ソフト等で自動計算されるので認識不要と思われるかも知れないが。
支払金額や預り金額が正しく認識されているかどうかを後で検証する際に役立つのでやはり必要。
で、上記の設定も大切だが、もっと精度アップに効果的な方法を発見したような・・・・そんな気がする。
それを書きたかったのだが力尽きたので、また次回にでも・・・。